对于新网站而言,还有什么比网站不被百度收录或编入索引更令人头疼?本文旨在帮助您发现可能导致百度无法为您的网站编制索引的可能原因。
如何查看百度的网站索引
如果要首先确定您的网页(或整个网站)未在百度中编入索引,请按以下步骤操作:
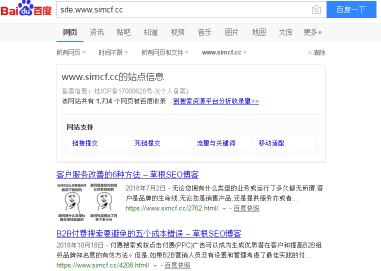
1.使用“site:ww.simcf.cc”进行查询,这将显示百度在其搜索引擎中为域编制索引的大概网址,如下图:
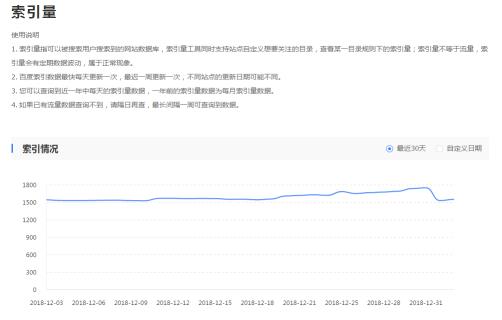
2.登录百度站长管理平台,转到索引量,可查看大概的索引数量,如下图:
如果页面没有生成200服务器响应代码,那么不要指望搜索引擎将它们编入索引(或者如果它们曾经已经索引则保持索引)。有时URL会被意外重定向,产生404 0r 500错误,具体取决于CMS问题,服务器问题或用户错误。请快速检查以确保正确加载页面的网址。
2.Robots.txt阻止网站的/robots.txt文件(大部分位于网站根目录下)为百度提供了抓取命令。如果网站上的某个特定网页缺少不被百度索引,那么robots.txt文件是首先要检查的地方之一,如果要查看URL是否被robots.txt文件阻止,请跳到百度站长管理平台进行“抓取诊断”测试,如下:
参考:robots.txt文件协议最佳设置技巧
网站上的某个网页可能无法在百度中编入索引的另一个常见原因是,它可能在网页的<head>中有一个“noindex”元机器人标记。当百度看到这个元机器人标签时,它是一个明确的指示,它不应该索引页面。百度将始终尊重此命令,并且它可以有多种形式,具体取决于其编码方式:
以下是页面<head>中的内容截图:

要检查网页是否有“noindex”元机器人标记,请查看源代码并在<head>中查找代码。如果网站使用javascript进行渲染,则可能需要使用Google Chrome的“检查元素”功能才能正确查看<head>。
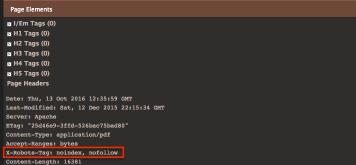
4.“Noindex”X-Robots标签与元机器人标签类似,X-robots标签提供了通过页面级标签控制百度索引的功能。但是,此标记用于特定页面或文档的标题响应中。它通常用于没有<head>的非HTML页面,例如PDF文件,DOC文件以及网站管理员希望远离百度索引的其他文件。“noindex”X-robots标签不太可能被意外应用,但您可以使用针对Chrome 的SEO Site Tools扩展程序进行检查。如下:
内容重复是任何SEO工作的风险,重复内容可能会使您的网页远离百度的索引,如果网页上重复内容的比例较大可能会使其排名不佳。如果您的网站上有大量类似内容的特定网页,则可能是因为您的网页未在百度中编入索引的主要原因(比如采集站的所有就会非常的慢)。
参考:关于网站重复内容的3个思考
6.整体指数缺乏价值特定页面或整个网站可能非常糟糕,以至于它无法为百度的索引提供足够的价值。例如,只有动态生成广告的联盟网站对用户没有什么价值。百度已经改进了算法,以避免排名(有时避免索引)这样的网站。
7.网站仍然是新的和未经证实的新网站不会被百度和其他搜索引擎迅速编入索引,它需要链接和其他信号才能让百度在其搜索结果中对网站进行索引和排名(可见)。这就是链接建设对新网站如此重要的原因,对于刚刚上线的网站而言,可以在上线后直接向百度提交链接请求,通常会在1小时左右收录网站主页。
如果网页加载缓慢且未修复,百度可能会随着时间的推移降低排名,该网页甚至可能会被搜索引擎移出索引。通常情况下,索引量会下降。
参考:网站打开速度优化指南
9.孤儿页面百度会抓取您的网站(和XML站点地图)以查找指向内容的链接,更新其索引并影响网站在搜索结果中的排名(以及其他因素)。如果百度无法在您的网站或外部网站上找到指向内容的链接,那么百度就不存在这些链接,所以它不会被编入索引,没有内部链接的页面被称为“孤立页面”,它们可能是降低百度索引编制的一个原因。
结论如果你觉得这些东西太技术化了,最好向SEO专家的咨询。如果你遇到困难,你需要确定你的时间有多宝贵。尝试解决百度索引和排名的深夜消费将变得令人厌倦。请记住,索引不等于排名。百度为您的网站编制索引后,网站的内容质量,链接建设以及品牌信号将决定网站的排名。但是,索引是SEO旅程的第一步。